LLMs Explained Like System Design.
Start with foundational concepts— neural networks, tokens, embeddings, vectors, layers—and learn how they fit together without getting deep into the math. Tap to explore and learn at your own pace.
Latest Insights
Stay updated with the most important developments in AI and machine learning
 Featured
FeaturedA practical guide to Google's UCP, the open standard for agentic commerce. Learn how to integrate AI-powered checkout into your products, what architectural decisions to consider, and where the opportunities lie.
 Featured
FeaturedLearn the core architectural patterns for building AI agents—ReAct, planning, reflection, tool use, and multi-agent systems—explained for engineers who think in system design.
 Featured
FeaturedLearn how semantic search uses embeddings and vectors to find information by meaning, not just keywords—explained for engineers who know SQL.
 Featured
FeaturedThe era of downloading dozens of apps to accomplish simple tasks is ending. AI platforms like ChatGPT are evolving into operating systems where natural language becomes the interface to everything. Here's what the future of apps really looks like.
 Featured
FeaturedLLMs don't 'think'—they predict tokens. Yet they solve math problems, debug code, and plan multi-step tasks. This guide explains the mechanics behind reasoning in language models and why reasoning agents represent the next frontier.
 Featured
FeaturedYour RAG system answers questions. But what if it could solve problems? Learn how agentic AI transforms retrieval from Q&A into goal-directed systems that plan, act, and iterate.
How Reasoning Works in LLMs: From Chain-of-Thought to Reasoning Agents
LLMs don't 'think'—they predict tokens. Yet they solve math problems, debug code, and plan multi-step tasks. This guide explains the mechanics behind reasoning in language models and why reasoning agents represent the next frontier.
So, What is Agentic AI?
Your RAG system answers questions. But what if it could solve problems? Learn how agentic AI transforms retrieval from Q&A into goal-directed systems that plan, act, and iterate.
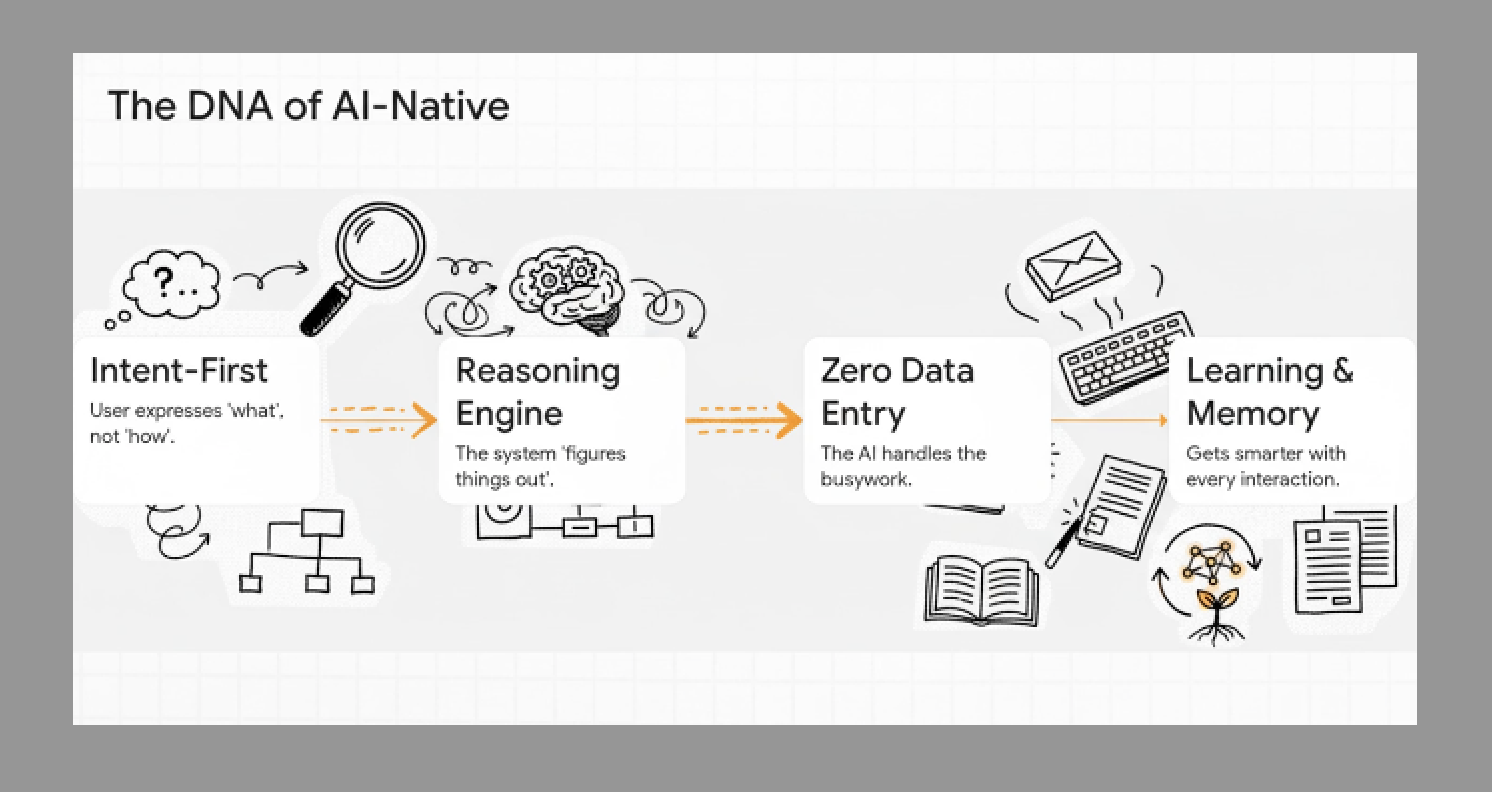
Your Software Is Getting a Brain: 5 Signs You're Using an App of the Future
AI-native software isn't just adding AI features—it's fundamentally reimagining how we interact with applications. Discover the five transformative changes that signal you're using the software of the future.

Prompt Injection: Must Read for RAG engineers
A hidden resume text hijacks your hiring AI. A malicious email steals your passwords. Welcome to prompt injection—the critical vulnerability every RAG engineer must understand and defend against.

LLM Quantization Guide: FP32 vs Int8 vs GGUF
Why shrinking your model is like compressing a JPEG—and how to do it without lobotomizing your AI.

The Bedrock of Intelligence: From a Single Neuron to the Heart of an LLM
Peel back the layers of Large Language Models to understand the artificial neuron, the power of ReLU, and how these simple units power the massive Transformer architecture.
From each section

