AI Embeddings Explained: From Text to Vectors
Learn what embeddings are, how embedding models create them, how to store and query them efficiently, and what trade-offs to consider when scaling large RAG systems.
“If data is the body of AI, embeddings are its nervous system — transmitting meaning through numbers.”
The Challenge: Computers Don’t Understand Words
You just typed:
“The cat sat on the roof-top”
Before a Large Language Model can even think about what this means, it has to solve a very boring but absolutely critical problem:
Computers don’t understand words. They only understand numbers.
So the very first job of any modern LLM is to translate your text into a long list of numbers that somehow capture the meaning, grammar, and even emojis of what you wrote.
This happens in two separate stages that always work together:
- Tokenization → chop your text into small pieces (tokens) and give each piece an ID number
- Embedding → turn that ID into a rich, high-dimensional vector that actually carries meaning
Let’s walk through both steps like we’re building the system from scratch.
Step 1: Tokenization — Breaking Text into Tokens
Why can’t we just use whole words?
If we gave every English word its own ID, we’d need millions of IDs (English has hundreds of thousands of words, plus names, typos, new slang, numbers, etc.). That’s wasteful and impossible to keep updated.
Even worse: what about languages like German that glue words together (“Donaudampfschifffahrtsgesellschaft”)? Or Turkish that adds dozens of suffixes to a single root?
So instead of whole words, modern LLMs chop text into subword units — pieces that are bigger than letters but usually smaller than full words.
The Most Famous Method: Byte-Pair Encoding (BPE)
Think of BPE as the “smart scissors” of tokenization. Here’s how it learns where to cut:
Training Phase (done once by the model creators)
- Start with all individual characters and give them IDs.
- Look at a giant pile of text and repeatedly ask: “Which two pieces appear next to each other most frequently?” Merge those two into a new, bigger piece and give it a new ID.
- Repeat tens of thousands of times.
Example (super simplified):
- “hug” appears a lot → create token “hug”
- “hugging” appears a lot → create token “hugging”
- “face” appears a lot → create token “face”
- But “hug” + “gingface” almost never appears together → keep them separate
Eventually you end up with a vocabulary of ~32k–160k tokens (depending on the model) that covers:
- Common full words (“the”, “hello”, “cat”)
- Common endings (“-ing”, “-ed”, “-ly”)
- Parts of rare words so they can be assembled later
Popular vocabularies you’ve probably heard of:
- GPT-2/GPT-4 → uses BPE
- Llama, Gemma, Mistral → uses Byte-level BPE (works on raw bytes, great for code and emojis)
- Claude → uses a custom tokenizer (similar idea)
What Actually Happens When You Type Something
Let’s take our sentence again:
“The cat sat on the roof-top”
A typical modern tokenizer (e.g., Llama 3’s) might split it like this:
Token | Token ID (example) |
|---|---|
The | 450 |
cat | 8615 |
sat | 1181 |
on | 356 |
the | 278 |
roof | 1056 |
- | 23 |
top | 1203 |
(end) | (maybe ) |
Total: ~7–9 tokens instead of 6 words. Emojis usually get their own token — that’s why models handle them so well.
Step 2: Embeddings — From Token ID to Meaningful Vector
Now we have a list of integers: [450, 8615, 1181, 356, 278, 1056, 23, 1203]
Still meaningless to a neural network.
The embedding layer is literally just a giant lookup table.
The Embedding Table (The Model’s Dictionary)
Imagine a spreadsheet with:
- Rows = every token ID in the vocabulary (say 128,000 rows)
- Columns = the embedding dimension (modern models use 4096, 8192, or even more)
Each row is a list of numbers (a vector) that represents “what this token means” in a way the Transformer can work with.
Example (tiny 3-dimensional toy embeddings):
Token ID | Token | Embedding Vector |
|---|---|---|
450 | The | [0.1, -0.8, 0.3] |
8615 | cat | [0.9, 0.2, -0.7] |
1056 | moon | [-0.4, 0.9, 0.6] |
In real models these vectors are thousands of numbers long, and they’re learned during training.
What Actually Happens Inside the Model
When your list of token IDs enters the model:
- For each ID, do a simple table lookup → grab its vector
- Stack all vectors into a matrix:
Shape becomes
[sequence_length × embedding_dimension]e.g.,[9 tokens × 8192 dimensions] - Add positional embeddings (more on that in the next article)
- Feed this big matrix straight into the first Transformer layer
That’s it. No complex math yet — just looking up numbers in a table.
How Embedding Spaces Are Created
This “semantic map” isn’t handcrafted. It’s learned.
Embedding models are trained on large text corpora using self-supervised learning. Here’s a simplified view of how they learn:
-
Objective: Teach the model to predict which sentences or words are semantically related. Example: “The weather is sunny” should be closer to “It’s a bright day” than “I’m making pasta.”
-
Mechanism: The model adjusts its internal parameters so that similar sentences end up closer in vector space.
-
Mathematics: Behind the scenes, this is achieved through contrastive learning or masked language modeling, where similarity is computed using cosine distance between vectors.
After millions of such updates, the model’s vector space becomes rich in meaning — a geometry of language.
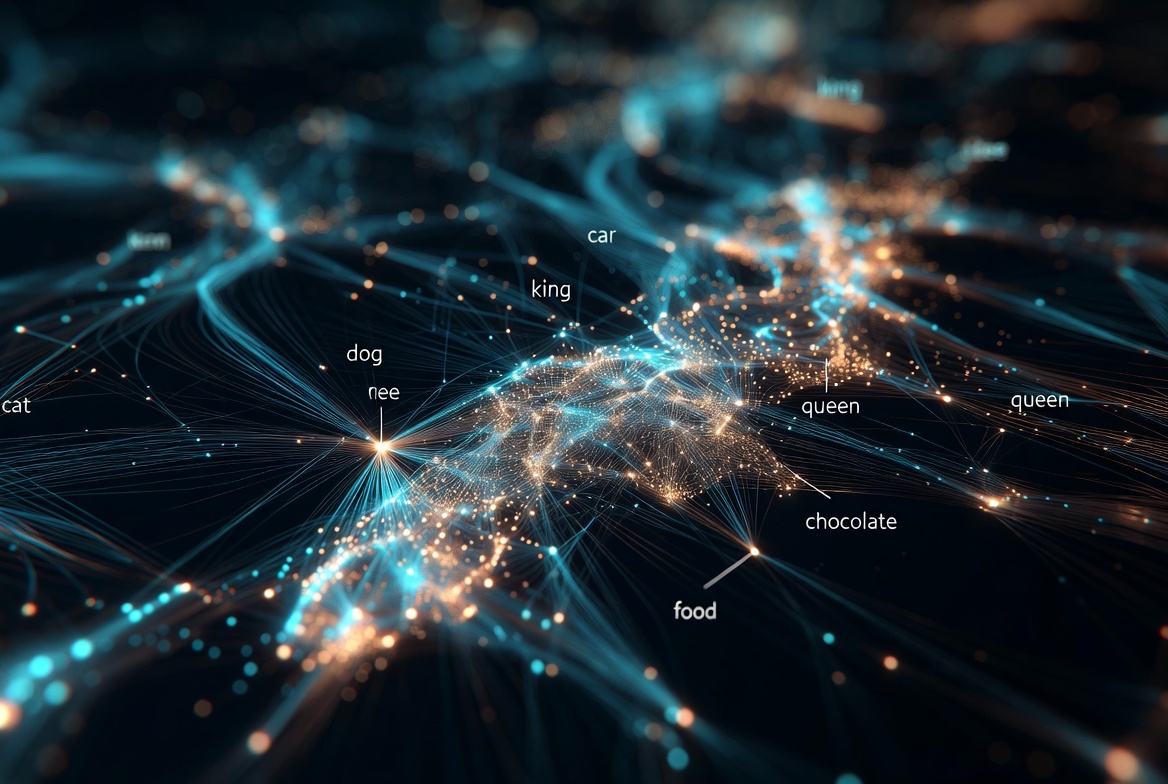
- Words with similar meanings end up with similar vectors → “cat” vector is close to “kitten” vector, far from “rocket”
- Simple arithmetic works! → vector(“king”) − vector(“man”) + vector(“woman”) ≈ vector(“queen”)
- Grammar and role are encoded too → verbs cluster together, subjects cluster together
Different models create different “maps of meaning.”
- Small models (like MiniLM) learn coarse relationships.
- Large models (like bge-large or OpenAI text-embedding-3-large) capture fine-grained nuance, analogies, and contextual subtleties.
This is why the Transformer can later “pay attention” so effectively — it’s working with rich, meaningful numbers from the very first layer.
Why “king – man + woman ≈ queen” Actually Works
This famous example feels like wizardry the first time you see it, but it’s just a happy side-effect of how embeddings are trained.
Modern embedding models (and the big LLMs that contain them) are trained on predicting the next word in trillions of sentences.
During that process, the model sees patterns like these over and over:
Pattern we see billions of times | What the model learns internally |
|---|---|
“The king sat on his throne” | “king” often appears with male royal words (he, his, prince…) |
“The queen sat on her throne” | “queen” appears with almost the exact same words except gender |
“The king loves his wife” | wife → queen connection |
“The queen loves her husband” | husband → king connection |
So the training objective forces the model to push the vectors for “king” and “queen” very close to each other — because they appear in nearly identical contexts.
The only consistent difference across billions of examples is the gender dimension.
Result:
If you subtract the “maleness” direction (vector“man”) from “king” and add the “femaleness” direction (vector“woman”), you land almost exactly on “queen”.
The same thing happens with capitals:
- France → Paris
- Germany → Berlin
- Japan → Tokyo
Because the training data always says “Paris is the capital of France”, “Berlin is the capital of Germany”, etc.
These clean linear relationships aren’t programmed in — they emerge automatically from the statistics of language.
That’s why embeddings don’t just memorize words. They accidentally discover the underlying structure of ideas.
Why Different Models Create Different Spaces
Just like maps drawn by different cartographers vary slightly, each embedding model builds its own coordinate system.
That means:
- Two models won’t produce comparable vectors for the same text.
- You can’t mix embeddings from different models in the same database.
- Retrieval quality depends heavily on how the model organizes meaning.
Example:
- A multilingual model may group “perro” (Spanish) near “dog.”
- A monolingual English model won’t — it has never seen “perro.”
Therefore, when designing your RAG system:
- Choose one model family and stick with it for both indexing and querying.
- Re-embedding is necessary if you switch models later.
Embedding Across Multiple Languages
Multilingual models (like LaBSE, bge-m3, or e5-multilingual) are trained on text pairs across languages.
They learn that:
“Hello world” ≈ “Hola mundo” ≈ “Bonjour le monde”
This allows a single vector space where sentences in different languages align by meaning.
Applications:
- Cross-language search (“search in English, retrieve Spanish docs”)
- Multilingual chatbots
- Global knowledge retrieval systems
But multilingual embeddings often come at a cost:
- Slightly lower accuracy in each language compared to monolingual models.
- Larger models and slower inference due to broader vocabulary coverage.
The Complete Pipeline in One Picture
Your text
↓
Tokenizer → [450, 8615, 1181, ...] (list of integers)
↓
Embedding Lookup Table
↓
[[0.12, -0.45, 0.89, ...], (sequence_length × 8192 matrix of floats)
[0.91, 0.03, -0.67, ...],
...]
↓
→ First Transformer layer (now the real thinking begins)Quick Recap
Stage | Input | Output | Purpose |
|---|---|---|---|
Tokenization | Raw text | List of token IDs | Break text into manageable chunks |
Embedding | List of token IDs | Matrix of dense vectors | Turn IDs into rich meaning |
Transformer | Matrix of vectors | Predictions, answers, images… | Do the actual intelligence |
That’s literally how every word you type becomes something an LLM can reason about.