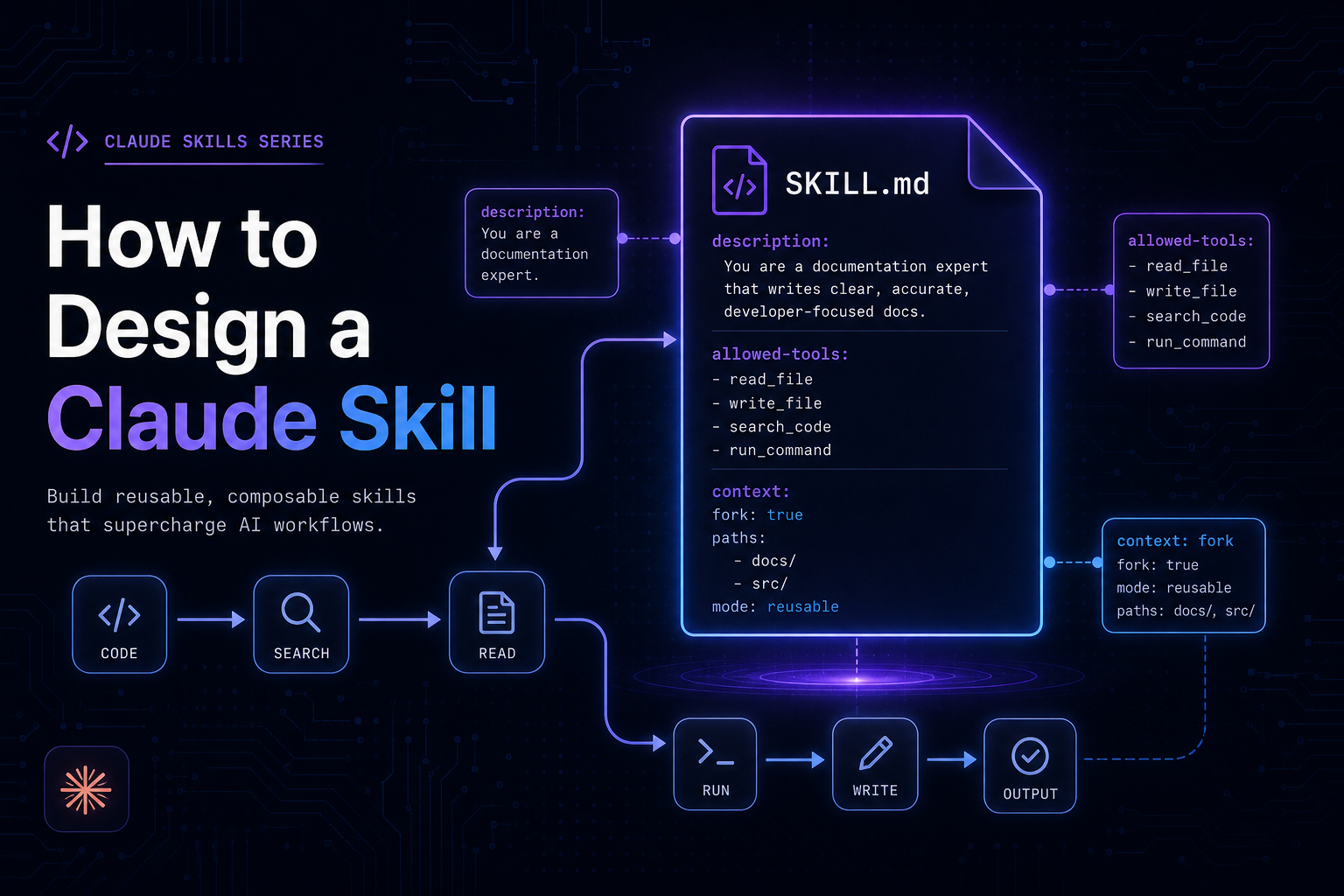
Inside a RAG Pipeline: The 5 Building Blocks Explained
Understand the five essential components of a Retrieval-Augmented Generation (RAG) pipeline and how they work together to make AI smarter, faster, and more reliable.

Why This Matters
When people hear “RAG pipeline,” it often sounds like some mysterious black box. But in reality, a Retrieval-Augmented Generation pipeline is just a smart workflow where different parts of the system do specific jobs.
Think of it like a relay race — each runner hands the baton to the next. By the end, the AI gives you an answer that’s both fluent and grounded in facts.
Let’s break down the five key building blocks that make RAG work.

1. The Knowledge Source
This is where all your information lives. It could be:
- PDFs and documents
- A customer support knowledge base
- Product manuals
- Databases or even websites
Without this, the AI has nothing to “look up.” The quality of your RAG system starts here — clean, well-organized data is crucial.
2. The Retriever
Imagine asking a librarian for books about “space travel.” The librarian doesn’t give you the whole library; they hand-pick the most relevant books.
That’s exactly what the retriever does. It searches the knowledge source and pulls out a handful of relevant chunks of text.
Popular retrievers use vector databases like Pinecone, Weaviate, or Milvus, which can find “similar” meanings instead of just keyword matches.
3. The Embeddings
But how does the system know which text is similar? That’s where embeddings come in.
An embedding is a way of turning text into numbers (vectors) that capture meaning.
- Example: “doctor” and “physician” will have similar embeddings.
- Example: “cat” and “car” will be far apart in this vector space.
These embeddings power the retriever’s ability to find the right context.
4. The Generator (LLM or SLM)
Once the retriever hands over the relevant documents, the generator takes over. This can be either a Large Language Model (LLM) like GPT-4o, Claude, or Llama — or a Small Language Model (SLM) optimized for efficiency.
- LLMs are versatile, handle long contexts, and excel at nuanced, multi-step reasoning.
- SLMs are lighter, cheaper, and faster — ideal for simpler queries, FAQs, or on-device/private use.
In many production systems, an SLM handles quick or repetitive questions and escalates tougher ones to an LLM, balancing cost and performance.
Either way, the generator’s job is to read the retrieved snippets and craft a natural-language response:
- Without RAG: the model might guess or hallucinate.
- With RAG: the model answers using the provided context.
Think of it as the storyteller of the system — turning raw data into a polished answer.
5. The Output Layer
Finally, the system delivers the response back to you. Depending on the use case, the output might be:
- A chatbot answer
- A summarized report
- A search result with citations
- A generated email draft
Some advanced RAG pipelines also show which sources were used, building trust by citing references.
Putting It All Together
Here’s the flow: Knowledge Source → Embeddings → Retriever → Generator → Output
Each block is simple on its own, but together they form a powerful pipeline that bridges the gap between AI’s creativity and factual accuracy.
Key Takeaways
- A RAG pipeline isn’t magic; it’s a workflow of five clear steps.
- The knowledge source feeds the system.
- Embeddings + retriever ensure the right info gets pulled.
- The generator (LLM or SLM) crafts the final response.
- The output layer delivers it in a user-friendly way.
Next time someone mentions a “RAG pipeline,” you’ll know it’s just these five building blocks working together — like a team passing the baton to deliver smarter answers.